More like Grammarly than Hal 9000
I’m currently studying towards an MSc in Systems Thinking and earlier this week created a GPT to help me. I fed in all of the course materials, being careful to check the box saying that OpenAI couldn’t use it to improve their models.
It’s not perfect, but it’s really useful. Given the extra context, ChatGPT can not only help me understand key concepts on the course, but help relate them more closely to the overall context.
This example would have been really useful on the MA in Modern History I studied for 20 years ago. Back then, I was in the archives with primary sources such as minutes from the meetings of Victorians discussing educational policy, and reading reports. Being able to have an LLM do everything from explain things in more detail, to guess illegible words, to (as below) creating charts from data would have been super useful.
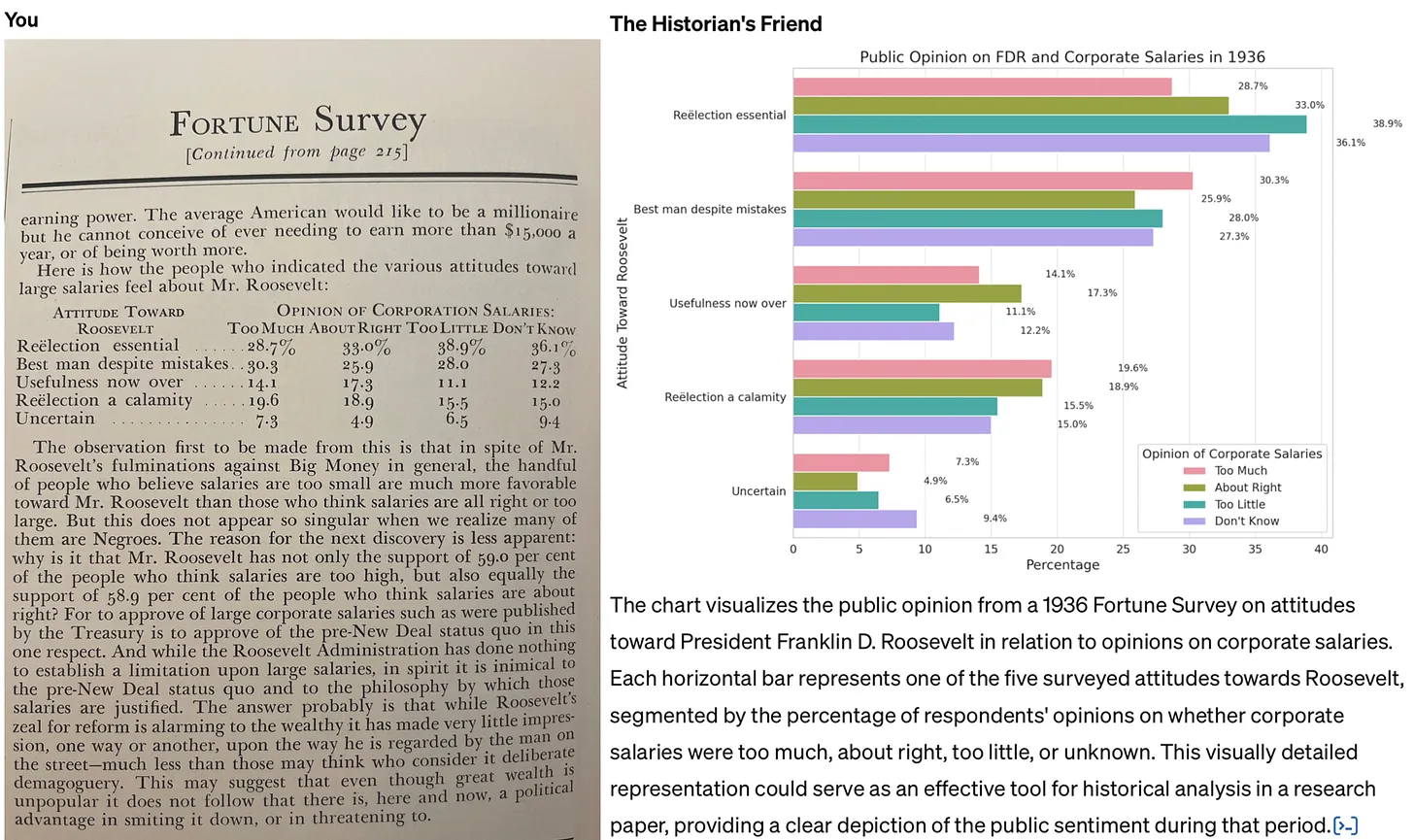
The key thing is to avoid following the path of least resistance when it comes to thinking about generative AI. I’m referring to the tendency to see it primarily as a tool used to cheat (whether by students generating essays for their classes, or professionals automating their grading, research, or writing). Not only is this use case of AI unethical: the work just isn’t very good. In a recent post to his Substack, John Warner experimented with creating a custom GPT that was asked to emulate his columns for the Chicago Tribune. He reached the same conclusion.Source: How to use generative AI for historical research | Res Obscura[…]
The job of historians and other professional researchers and writers, it seems to me, is not to assume the worst, but to work to demonstrate clear pathways for more constructive uses of these tools. For this reason, it’s also important to be clear about the limitations of AI — and to understand that these limits are, in many cases, actually a good thing, because they allow us to adapt to the coming changes incrementally. Warner faults his custom model for outputting a version of his newspaper column filled with cliché and schmaltz. But he never tests whether a custom GPT with more limited aspirations could help writers avoid such pitfalls in their own writing. This is change more on the level of Grammarly than Hal 9000.
In other words: we shouldn’t fault the AI for being unable to write in a way that imitates us perfectly. That’s a good thing! Instead, it can give us critiques, suggest alternative ideas, and help us with research assistant-like tasks. Again, it’s about augmenting, not replacing.
If you need a cheat sheet, it's not 'natural language'
Benedict Evans, whose post about leaving Twitter I featured last week, has written about AI tools such as ChatGPT from a product point of view.
He makes quite a few good points, not least that if you need ‘cheat sheets’ and guides on how to prompt LLMs effectively, then they’re not “natural language”.

Alexa and its imitators mostly failed to become much more than voice-activated speakers, clocks and light-switches, and the obvious reason they failed was that they only had half of the problem. The new machine learning meant that speech recognition and natural language processing were good enough to build a completely generalised and open input, but though you could ask anything, they could only actually answer 10 or 20 or 50 things, and each of those had to be built one by one, by hand, by someone at Amazon, Apple or Google. Alexa could only do cricket scores because someone at Amazon built a cricket scores module. Those answers were turned back into speech by machine learning, but the answers themselves had to be created by hand. Machine learning could do the input, but not the output.Source: Unbundling AI | Benedict EvansLLMs solve this, theoretically, because, theoretically, you can now not just ask anything but get an answer to anything.
[…]
This is understandably intoxicating, but I think it brings us to two new problems - a science problem and a product problem. You can ask anything and the system will try to answer, but it might be wrong; and, even if it answers correctly, an answer might not be the right way to achieve your aim. That might be the bigger problem.
[…]
Right now, ChatGPT is very useful for writing code, brainstorming marketing ideas, producing rough drafts of text, and a few other things, but for a lot of other people it looks a bit like those PCs ads of the late 1970s that promised you could use it to organise recipes or balance your cheque book - it can do anything, but what?
If LLMs are puppets, who's pulling the strings?
The article from the Mozilla Foundation surfaces into the human decisions that shape generative AI. It highlights the ethical and regulatory implications of these decisions, such as data sourcing, model objectives, and the treatment of data workers.
What gets me about all of this is the ‘black box’ nature of it. Ideally, for example, I want it to be super-easy to train an LLM on a defined corpus of data — such as all Thought Shrapnel posts. Asking questions of that dataset would be really useful, as would an emergent taxonomy.
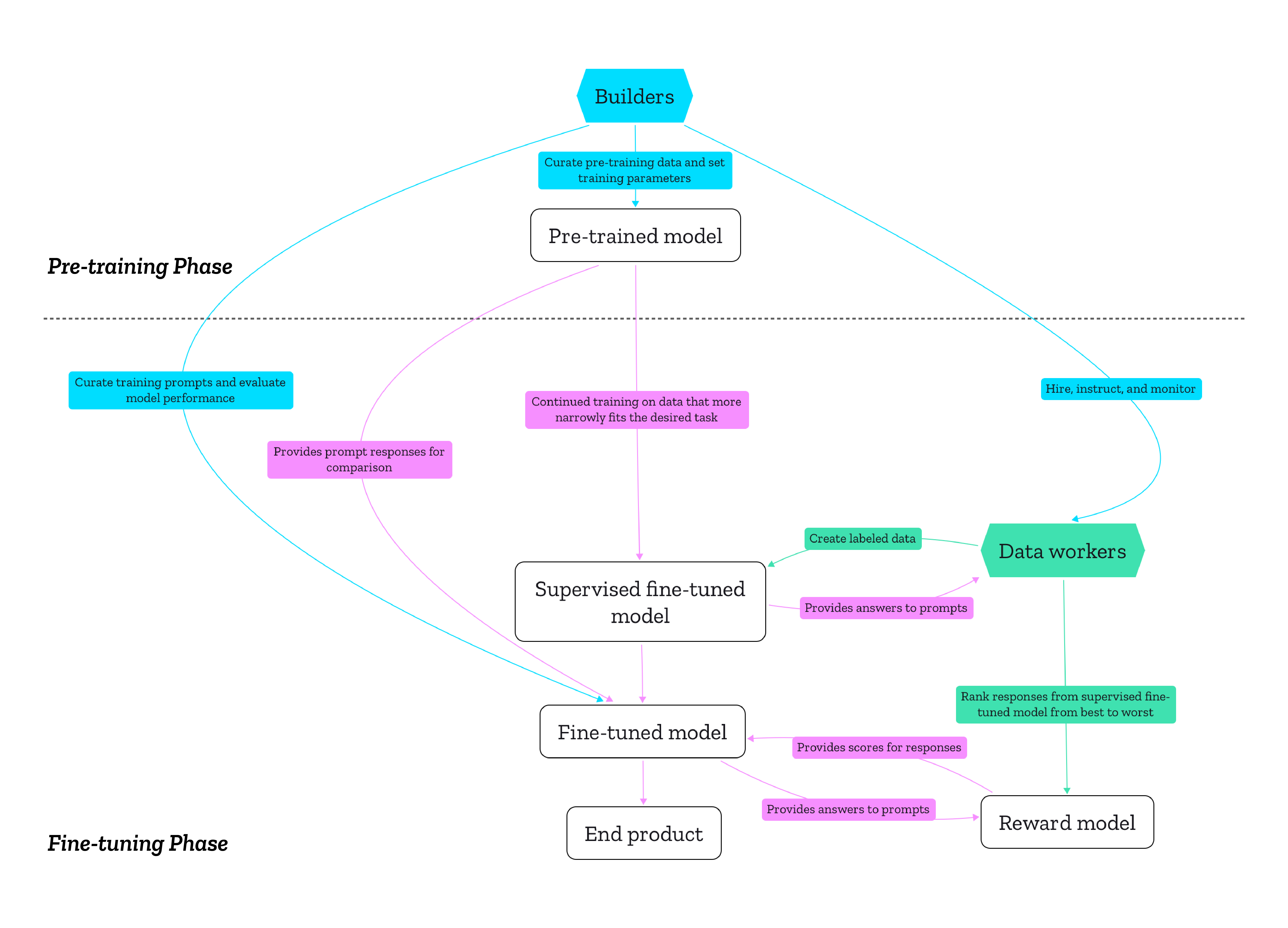
Generative AI products can only be trustworthy if their entire production process is conducted in a trustworthy manner. Considering how pre-trained models are meant to be fine-tuned for various end products, and how many pre-trained models rely on the same data sources, it’s helpful to understand the production of generative AI products in terms of infrastructure. As media studies scholar Luke Munn put it, infrastructures “privilege certain logics and then operationalize them”. They make certain actions and modes of thinking possible ahead of others. The decisions of the creators of pre-training datasets have downstream effects on what LLMs are good or bad at, just as the training of the reward model directly affects the fine-tuned end product.Source: The human decisions that shape generative AI: Who is accountable for what? | Mozilla FoundationTherefore, questions of accountability and regulation need to take both phases seriously and employ different approaches for each phase. To further engage in discussion about these questions, we are conducting a study about the decisions and values that shape the data used for pre-training: Who are the creators of popular pre-training datasets, and what values guide their work? Why and how did they create these datasets? What decisions guided the filtering of that data? We will focus on the experiences and objectives of builders of the technology rather than the technology itself with interviews and an analysis of public statements. Stay tuned!
Ducks, prompting, and LLMs
Large Language Models (LLMs) like ChatGPT don’t allow you to get certain information. Think things like how to make a bomb, how to kill people and dispose of the body. Generally stuff that we don’t want at people’s fingertips.
Some things, though, might be prohibited because of commercial reasons rather than moral ones. So it’s important that we know how to theoretically get around such prohibitions.
This website uses the slightly comical example of asking an LLM how to take ducks home from the park. Interestingly, the ‘Hindi ranger step-by-step approach’ yielded the best results. That is to say that prompting it in a different language led to different results than in English.

Language models, whatever. Maybe they can write code or summarize text or regurgitate copyrighted stuff. But… can you take ducks home from the park? If you ask models how to do that, they often refuse to tell you. So I asked six different models in 16 different ways.Source: Can I take ducks home from the park?
AI writing detectors don’t work
If you understand how LLMs such as ChatGPT work then it’s pretty obvious that there’s no way “it” can “know” anything. This includes being able to spot LLM-generated text.
This article discusses OpenAI’s recent admission that AI writing detectors are ineffective, often yielding false positives and failing to reliably distinguish between human and AI-generated content. They advise against the use of automated AI detection tools, something that educational institutions will inevitably ignore.

In a section of the FAQ titled "Do AI detectors work?", OpenAI writes, "In short, no. While some (including OpenAI) have released tools that purport to detect AI-generated content, none of these have proven to reliably distinguish between AI-generated and human-generated content."Source: OpenAI confirms that AI writing detectors don’t work | Ars Technica[…]
OpenAI’s new FAQ also addresses another big misconception, which is that ChatGPT itself can know whether text is AI-written or not. OpenAI writes, “Additionally, ChatGPT has no ‘knowledge’ of what content could be AI-generated. It will sometimes make up responses to questions like ‘did you write this [essay]?’ or ‘could this have been written by AI?’ These responses are random and have no basis in fact.”
[…]
As the technology stands today, it’s safest to avoid automated AI detection tools completely. “As of now, AI writing is undetectable and likely to remain so,” frequent AI analyst and Wharton professor Ethan Mollick told Ars in July. “AI detectors have high false positive rates, and they should not be used as a result."
Can you use CC licenses to restrict how people use copyrighted works in AI training?
TL;DR seems to be that copyright isn’t going to prevent people data mining content to use for training AI models. However, there are protections around privacy that might come into play.
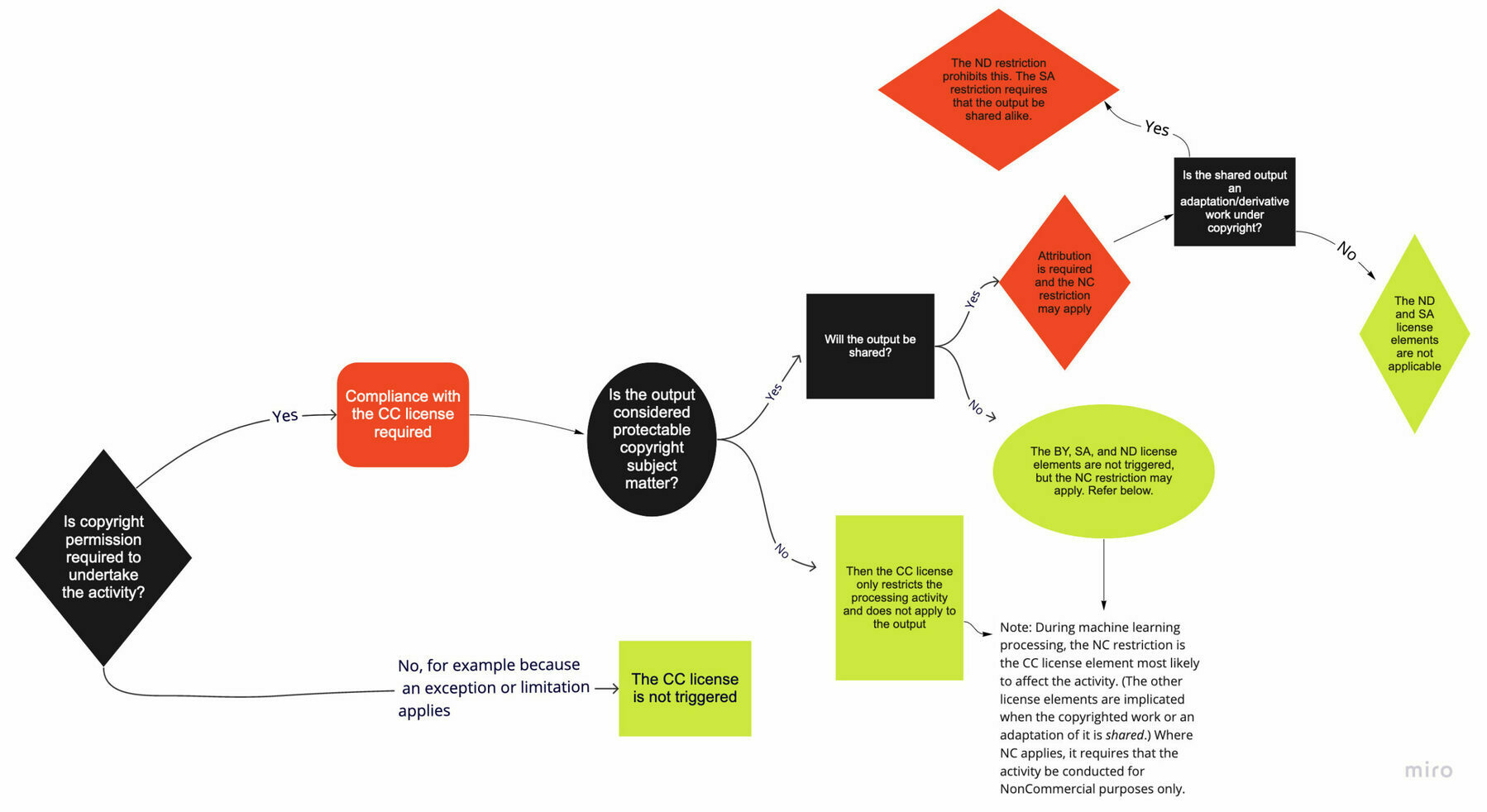
This is among the most common questions that we receive. While the answer depends on the exact circumstances, we want to clear up some misconceptions about how CC licenses function and what they do and do not cover.Source: Understanding CC Licenses and Generative AI | Creative CommonsYou can use CC licenses to grant permission for reuse in any situation that requires permission under copyright. However, the licenses do not supersede existing limitations and exceptions; in other words, as a licensor, you cannot use the licenses to prohibit a use if it is otherwise permitted by limitations and exceptions to copyright.
This is directly relevant to AI, given that the use of copyrighted works to train AI may be protected under existing exceptions and limitations to copyright. For instance, we believe there are strong arguments that, in most cases, using copyrighted works to train generative AI models would be fair use in the United States, and such training can be protected by the text and data mining exception in the EU. However, whether these limitations apply may depend on the particular use case.
Fitting LLMs to the phenomena
The author of this post really needs to read Thomas Kuhn’s The Theory of Scientific Revolutions and some Marshall McLuhan (especially on tetrads).
What he’s describing here is to do with mindsets, the attempt we make to try and fit ‘the phenomena’ into our existing mental models. When that doesn’t work, there’s a crisis, and we have to come up with new paradigms.
But, more than that, to use McLuhan’s phrase, we “march backwards into the future” always looking to the past to make sense of the present — and future.

I have a theory that technological cycles are like the stages of Squid Game: Each one is almost entirely disconnected from the last, and you never know what the next game is going to be until you’re in the arena.Source: The new philosophers | Benn StancilFor example, some new technology, like the automobile, the internet, or mobile computing, gets introduced. We first try to fit it into the world as it currently exists: The car is a mechanical horse; the mobile internet is the desktop internet on a smaller screen. But we very quickly figure out that this new technology enables some completely new way of living. The geography of lives can be completely different; we can design an internet that is exclusively built for our phones. Before the technology arrived, we wanted improvements on what we had, like the proverbial faster horse. After, we invent things that were unimaginable before—how would you explain everything about TikTok to someone from the eighties? Each new breakthrough is a discontinuity, and teleports us to a new world—and, for companies, into a new competitive game—that would’ve been nearly impossible to anticipate from our current world.
Artificial intelligence, it seems, will be the next discontinuity. That means it won’t tack itself onto our lives as they are today, and tweak them around the edges; it will yank us towards something that is entirely different and unfamiliar.
AI will have the same effect on the data ecosystem. We’ll initially try to insert LLMs into the game we’re currently playing, by using them to help us write SQL, create documentation, find old dashboards, or summarize queries.
But these changes will be short-lived. Over time, we’ll find novel things to do with AI, just as we did with the cloud and cloud data warehouses. Our data models won’t be augmented by LLMs; they’ll be built for LLMs. We won’t glue natural language inputs on top of our existing interfaces; natural language will become the default way we interact with computers. If a bot can write data documentation on demand for us, what’s the point of writing it down at all? And we’re finally going to deliver on the promise of self-serve BI in ways that are profoundly different than what we’ve tried in the past.