Bill Gates on why AI agents are better than Clippy
While there’s nothing particularly new in this post by Bill Gates, it’s nevertheless a good one to send to people who might be interested in the impact that AI is about to have on society.
Gates compares AI agents to Clippy which, he says, was merely a bot. After going through all of the advantages there will be to AI agents acting on your behalf, Gates does, to his credit, talk about privacy implications. He also touches on social conventions and how human norms interact with machine efficiency.
The thing that strikes me in all of this is something that Audrey Watters discussed a few months ago in relation to fitness technologies: will these technologies make us more like to live ‘templated lives’. In other words, are they helping support human flourishing, or nudging us towards lives that make more revenue for advertisers, etc.?

Agents will affect how we use software as well as how it’s written. They’ll replace search sites because they’ll be better at finding information and summarizing it for you. They’ll replace many e-commerce sites because they’ll find the best price for you and won’t be restricted to just a few vendors. They’ll replace word processors, spreadsheets, and other productivity apps. Businesses that are separate today—search advertising, social networking with advertising, shopping, productivity software—will become one business.Source: AI is about to completely change how you use computers | Bill Gates[…]
How will you interact with your agent? Companies are exploring various options including apps, glasses, pendants, pins, and even holograms. All of these are possibilities, but I think the first big breakthrough in human-agent interaction will be earbuds. If your agent needs to check in with you, it will speak to you or show up on your phone. (“Your flight is delayed. Do you want to wait, or can I help rebook it?”) If you want, it will monitor sound coming into your ear and enhance it by blocking out background noise, amplifying speech that’s hard to hear, or making it easier to understand someone who’s speaking with a heavy accent.
[…]
But who owns the data you share with your agent, and how do you ensure that it’s being used appropriately? No one wants to start getting ads related to something they told their therapist agent. Can law enforcement use your agent as evidence against you? When will your agent refuse to do something that could be harmful to you or someone else? Who picks the values that are built into agents?
[…]
But other issues won’t be decided by companies and governments. For example, agents could affect how we interact with friends and family. Today, you can show someone that you care about them by remembering details about their life—say, their birthday. But when they know your agent likely reminded you about it and took care of sending flowers, will it be as meaningful for them?
Perhaps switch to another search engine?
I use a lot of Google products. I’m typing this on a laptop on which I’ve installed ChromeOS Flex, I use Google Workspace at work, I’ve got a Google Assistant device in every room of our house, and now even my car has an infotainment system with it built in.
But I do take some precautions. I don’t use Google Search. I turn off my web history, watching history on YouTube, opt out of personalisation, and encrypt my Chrome browser sync with a password.
This article doesn’t surprise me, because Google’s core business is advertising. It’s still creepy though.

There have long been suspicions that the search giant manipulates ad prices, and now it’s clear that Google treats consumers with the same disdain. The “10 blue links,” or organic results, which Google has always claimed to be sacrosanct, are just another vector for Google greediness, camouflaged in the company’s kindergarten colors.Source: How Google Alters Search Queries to Get at Your Wallet | WIREDGoogle likely alters queries billions of times a day in trillions of different variations. Here’s how it works. Say you search for “children’s clothing.” Google converts it, without your knowledge, to a search for “NIKOLAI-brand kidswear,” making a behind-the-scenes substitution of your actual query with a different query that just happens to generate more money for the company, and will generate results you weren’t searching for at all. It’s not possible for you to opt out of the substitution. If you don’t get the results you want, and you try to refine your query, you are wasting your time. This is a twisted shopping mall you can’t escape.
Why would Google want to do this? First, the generated results to the latter query are more likely to be shopping-oriented, triggering your subsequent behavior much like the candy display at a grocery store’s checkout. Second, that latter query will automatically generate the keyword ads placed on the search engine results page by stores like TJ Maxx, which pay Google every time you click on them. In short, it’s a guaranteed way to line Google’s pockets.
The supermarket is a panopticon
My son’s now old enough to get ‘loyalty cards’ for supermarkets, coffee shops, and places to eat. He thinks this is great: free drinks! money off vouchers! What’s not to like? On a recent car journey, I explained why the only loyalty card I use is the one for the Co-op, and introduced him to the murky world of data brokers.
In this article, Ian Bogost writes in The Atlantic about the extensive data collection by retailers to personalise marketing. This not only predicts but also influences consumer behaviour, raising ethical concerns about the erosion of privacy and democratic ideals. Bogost argues that this data-driven approach shifts the power balance, allowing companies to manipulate consumer preferences.
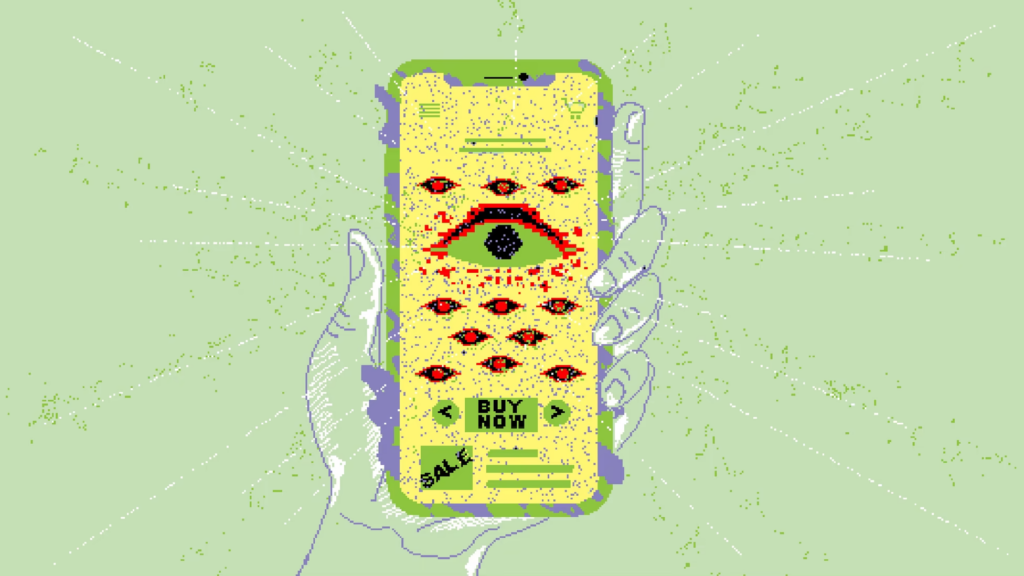
In marketing, segmentation refers to the process of dividing customers into different groups, in order to make appeals to them based on shared characteristics. Though always somewhat artificial, segments used to correspond with real categories or identities—soccer moms, say, or gamers. Over decades, these segments have become ever smaller and more precise, and now retailers have enough data to create a segment just for you. And not even just for you, but for you right now: They customize marketing messages to unique individuals at distinct moments in time.Source: You Should Worry About the Data Retailers Collect About You | The AtlanticYou might be thinking, Who cares? If stores can offer the best deals on the most relevant products to me, then let them do it. But you don’t even know which products are relevant anymore. Customizing offerings and prices to ever-smaller segments of customers works; it causes people to alter their shopping behavior to the benefit of the stores and their data-greedy machines. It gives retailers the ability, in other words, to use your private information to separate you from your money. The reason to worry about the erosion of retail privacy isn’t only because stores might discover or reveal your secrets based on the data they collect about you. It’s that they can use that data to influence purchasing so effectively that they’re rewiring your desires.
[…]
Ordinary people may not realize just how much offline information is collected and aggregated by the shopping industry rather than the tech industry. In fact, the two work together to erode our privacy effectively, discreetly, and thoroughly. Data gleaned from brick-and-mortar retailers get combined with data gleaned from online retailers to build ever-more detailed consumer profiles, with the intention of selling more things, online and in person—and to sell ads to sell those things, a process in which those data meet up with all the other information big Tech companies such as Google and Facebook have on you.“Retailing,” Joe Turow told me, “is the place where a lot of tech gets used and monetized.” The tech industry is largely the ad-tech industry. That makes a lot of data retail data. “There are a lot of companies doing horrendous things with your data, and people use them all the time, because they’re not on the public radar.” The supermarket, in other words, is a panopticon just the same as the social network.
Can you use CC licenses to restrict how people use copyrighted works in AI training?
TL;DR seems to be that copyright isn’t going to prevent people data mining content to use for training AI models. However, there are protections around privacy that might come into play.
This is among the most common questions that we receive. While the answer depends on the exact circumstances, we want to clear up some misconceptions about how CC licenses function and what they do and do not cover.Source: Understanding CC Licenses and Generative AI | Creative CommonsYou can use CC licenses to grant permission for reuse in any situation that requires permission under copyright. However, the licenses do not supersede existing limitations and exceptions; in other words, as a licensor, you cannot use the licenses to prohibit a use if it is otherwise permitted by limitations and exceptions to copyright.
This is directly relevant to AI, given that the use of copyrighted works to train AI may be protected under existing exceptions and limitations to copyright. For instance, we believe there are strong arguments that, in most cases, using copyrighted works to train generative AI models would be fair use in the United States, and such training can be protected by the text and data mining exception in the EU. However, whether these limitations apply may depend on the particular use case.
The only way to outlaw encryption is to outlaw encryption
An enjoyable take by The Register on the UK’s Online Safety Bill. I was particularly interested by the link to Veilid, a new secure peer-to-peer network for apps which is like the offspring of IPFS and Tor.
Many others have made the point about how much government ministers like the end-to-end encryption of their own WhatsApp communications. But they’d also like to break into, well… everyone else’s.

The official madness over data security is particularly bad in the UK. The British state is a world class incompetent at protecting its own data. In the past couple of weeks alone, we have seen the hacking of the Electoral Commission, the state body in charge of elections, the mass exposure of birth, marriage and death data, and the bulk release of confidential personnel information of a number of police forces, most notably the Police Service Northern Ireland. This was immediately picked up by terrorists who like killing police. It doesn't get worse than that.Source: Last rites for UK’s ridiculous Online Safety Bill | The RegisterThis same state is, of course, the one demanding that to “protect children,” it should get access to whatever encrypted citizen communication it likes via the Online Safety Bill, which is now rumored to be going through British Parliament in October. This is akin to giving an alcoholic uncle the keys to every booze shop in town to “protect children”: you will find Uncle in a drunken coma with the doors wide open and the stock disappearing by the vanload.
[…]
It is just stupidity stacked on incompetence balanced on political Dunning Krugerism, and the advent of Veilid drowns the lot in a tidal wave of foetid futility. What can a government do about a framework? What can it do about open source?
[…]
The only way to outlaw encryption is to outlaw encryption. Anything less will fail, as it is always possible in software to create kits of parts, all legal by themselves, that can be linked together to provide encryption with no single entity to legislate against. Our industry is fully aware of this. Criminals know it too. Ordinary people will learn it as well, if they have to. This information is free to everyone – except the politicians, it seems. For them, reality is far too expensive.
Teaching kids about anonymity
This website, riskyby.design, is a project of the 5Rights Foundation. It does a good job of talking about the benefits and drawbacks of anonymity in a way that isn’t patronising.

Online anonymity can take many forms, from pseudonyms that conceal “real” identities to private browsers or VPNs that allow users to be “untraceable.” There are also services designed specifically to grant users anonymity, known as “anonymous apps”.Source: Risky-By-Design | 5Rights FoundationOften conflated with privacy, true anonymity - the total absence of personally identifying information - is difficult to achieve in a digital environment where traces of ourselves are left every time we engage with a service. Anonymity is best considered on a continuum, ranging “from the totally anonymous to the thoroughly named”.
People have lots of reasons for being anonymous online. While anonymity affords a degree of protection to people like journalists, whistle-blowers and marginalised users, the lack of traceability that some types of anonymity offer may prevent people from being held accountable for their actions.
Sharing can be hard (online)
Granular permissions between private and public spaces is a hard problem to solve, as this blog post shows.
A few years ago, Apple acquired Color Labs, who were trying to solve the ‘share with contacts based on an ‘elastic social graph’. These days, I imagine this kind of problem being solved by Bonfire.
I wanted to share the pics and videos with the people I know, so they too can see (if they like) the awesome event that I just went to.Source: The rings of share – the unsolved problem of sharing | Rukshan’s BlogBut I had a problem that was recurring for a while, that is how to share different photos with the different connections that I have. There are photos that I can share publicly, and there are photos that I don’t want some people to see, such as my students, acquaintances, and work-related colleagues,
Meta may really be exiting Europe as soon as this year
Well, we can but hope. The backlash from Instagram-obsessed people would be too much for politicians to bear, however…

Meta has—as it must—warned its investors that it’s in deep trouble in Europe. It’s neither a threat nor a bluff, but rather a statement of fact: without a successor to the U.S.-EU Privacy Shield deal, which the EU’s top court nuked a couple of years back, Facebook and Instagram will be forced to pack up and abandon the European market.Source: Even Meta’s critics don’t grasp how likely it is that Facebook and Instagram will soon have to exit Europe | FortuneIndeed, this uncomfortable reality was made clearer last month, when Ireland’s privacy regulator submitted a draft decision to its EU peers that would ban Facebook and Insta from transferring Europeans’ personal data to the U.S., because there is no longer any legal basis for these transfers to continue.
[…]
I find it astonishing that even Facebook’s critics, let alone the markets, haven’t glommed onto the reality of the situation. I suspect the culprit is a deep-seated notion that Mark Zuckerberg’s all-powerful company can somehow fix this by modifying its legendarily bad privacy behavior—as though it had some brilliant solution hidden up its sleeve, just waiting until the last possible second before pulling it out.
Image: created using Midjourney
Should governments track supermarket purchases?
We booked a holiday to France this week and used Tesco vouchers to pay for the Eurotunnel crossing. These Tesco vouchers are a kind of payment-in-kind for the data they gather (and presumably sell) about our grocery purchases.
I use both Google Pay and Garmin Pay so that I don’t have to take a wallet with me everywhere. It’s convenient, but these two tech companies — as well as my bank — know a lot about my purchasing habits.
So, from that point of view, it seems odd to wring our hands about the State knowing more about grocery purchases. But the point, I guess, is that in this case there’s no way to escape it, no opt-out.
Statistics Norway (SSB) is the state-owned entity responsible for collecting, producing and communicating statistics related to the economy, population and society at national, regional and local levels.Source: Norway to Track All Supermarket Purchases | Life in NorwayBecause everything about an individual living in Norway is linked to their fødselnummer (birth number), SSB already knows where you live, what you earn and what’s on your criminal record.
However, according to a report by NRK, they now want to know where you shop, and what you buy.
SSB has ordered Norway’s major supermarket chains NorgesGruppen, Coop, Bunnpris and Rema 1000 to share all their receipt data with the agency. Nets, the payment processor that is responsible for 80% of transactions, will also need to provide data.
[…]
SSB claims they want a less time-consuming way of collecting and analysing household consumption statistics in order to inform tax policy, social assistance and child allowance.
[…]
SSB is adamant that they are only concerned with statistics at a group level: “When the purchases are linked to a household, it will be possible in the consumption statistics to analyze socio-economic and regional differences in consumption, and link it to variables such as income, education and place of residence.”
Should governments track supermarket purchases?
We booked a holiday to France this week and used Tesco vouchers to pay for the Eurotunnel crossing. These Tesco vouchers are a kind of payment-in-kind for the data they gather (and presumably sell) about our grocery purchases.
I use both Google Pay and Garmin Pay so that I don’t have to take a wallet with me everywhere. It’s convenient, but these two tech companies — as well as my bank — know a lot about my purchasing habits.
So, from that point of view, it seems odd to wring our hands about the State knowing more about grocery purchases. But the point, I guess, is that in this case there’s no way to escape it, no opt-out.
Statistics Norway (SSB) is the state-owned entity responsible for collecting, producing and communicating statistics related to the economy, population and society at national, regional and local levels.Source: Norway to Track All Supermarket Purchases | Life in NorwayBecause everything about an individual living in Norway is linked to their fødselnummer (birth number), SSB already knows where you live, what you earn and what’s on your criminal record.
However, according to a report by NRK, they now want to know where you shop, and what you buy.
SSB has ordered Norway’s major supermarket chains NorgesGruppen, Coop, Bunnpris and Rema 1000 to share all their receipt data with the agency. Nets, the payment processor that is responsible for 80% of transactions, will also need to provide data.
[…]
SSB claims they want a less time-consuming way of collecting and analysing household consumption statistics in order to inform tax policy, social assistance and child allowance.
[…]
SSB is adamant that they are only concerned with statistics at a group level: “When the purchases are linked to a household, it will be possible in the consumption statistics to analyze socio-economic and regional differences in consumption, and link it to variables such as income, education and place of residence.”
The rise of first-party online tracking
In a startling example of the Matthew effect of accumulated advantage, the incumbent advertising giants are actually being strengthened by legislation aimed to curb their influence. Because, of course.

Source: How You’re Still Being Tracked on the Internet | The New York TimesFor years, digital businesses relied on what is known as “third party” tracking. Companies such as Facebook and Google deployed technology to trail people everywhere they went online. If someone scrolled through Instagram and then browsed an online shoe store, marketers could use that information to target footwear ads to that person and reap a sale.
[...]Now tracking has shifted to what is known as “first party” tracking. With this method, people are not being trailed from app to app or site to site. But companies are still gathering information on what people are doing on their specific site or app, with users’ consent. This kind of tracking, which companies have practiced for years, is growing.
[...]The rise of this tracking has implications for digital advertising, which has depended on user data to know where to aim promotions. It tilts the playing field toward large digital ecosystems such as Google, Snap, TikTok, Amazon and Pinterest, which have millions of their own users and have amassed information on them. Smaller brands have to turn to those platforms if they want to advertise to find new customers.
Big Tech companies may change their names but they will not voluntarily change their economics
I based a good deal of Truth, Lies, and Digital Fluency, a talk I gave in NYC in December 2019, on the work of Shoshana Zuboff. Writing in The New York Times, she starts to get a bit more practical as to what we do about surveillance capitalism.
As Zuboff points out, Big Tech didn’t set out to cause the harms it has any more than fossil fuel companies set out to destroy the earth. The problem is that they are following economic incentives. They’ve found a metaphorical goldmine in hoovering up and selling personal data to advertisers.
Legislating for that core issue looks like it could be more fruitful in terms of long-term consequences. Other calls like “breaking up Big Tech” are the equivalent of rearranging the deckchairs on the Titanic.

Democratic societies riven by economic inequality, climate crisis, social exclusion, racism, public health emergency, and weakened institutions have a long climb toward healing. We can’t fix all our problems at once, but we won’t fix any of them, ever, unless we reclaim the sanctity of information integrity and trustworthy communications. The abdication of our information and communication spaces to surveillance capitalism has become the meta-crisis of every republic, because it obstructs solutions to all other crises.Source: You Are the Object of Facebook’s Secret Extraction Operation | The New York Times[…]
We can’t rid ourselves of later-stage social harms unless we outlaw their foundational economic causes. This means we move beyond the current focus on downstream issues such as content moderation and policing illegal content. Such “remedies” only treat the symptoms without challenging the illegitimacy of the human data extraction that funds private control over society’s information spaces. Similarly, structural solutions like “breaking up” the tech giants may be valuable in some cases, but they will not affect the underlying economic operations of surveillance capitalism.
Instead, discussions about regulating big tech should focus on the bedrock of surveillance economics: the secret extraction of human data from realms of life once called “private.” Remedies that focus on regulating extraction are content neutral. They do not threaten freedom of expression. Instead, they liberate social discourse and information flows from the “artificial selection” of profit-maximizing commercial operations that favor information corruption over integrity. They restore the sanctity of social communications and individual expression.
No secret extraction means no illegitimate concentrations of knowledge about people. No concentrations of knowledge means no targeting algorithms. No targeting means that corporations can no longer control and curate information flows and social speech or shape human behavior to favor their interests. Regulating extraction would eliminate the surveillance dividend and with it the financial incentives for surveillance.
UK government adviser warns against plans to force the NHS to share data with police forces
It’s entirely unsurprising that governments should seek to use the pandemic as cover for hoovering up data about its citizens. However, it’s up to us to resist this.

Plans to force the NHS to share confidential data with police forces across England are “very problematic” and could see patients giving false information to doctors, the government’s data watchdog has warned.Source: Plans to hand over NHS data to police sparks warning from government adviser | The Independent[…]
Dr Nicola Byrne also warned that emergency powers brought in to allow the sharing of data to help tackle the spread of Covid-19 could not run on indefinitely after they were extended to March 2022.
Dr Byrne, 46, who has had a 20-year career in mental health, also warned against the lack of regulation over the way companies were collecting, storing and sharing patient data via health apps.
She told The Independent she had raised concerns with the government over clauses in the Police, Crime, Sentencing and Courts Bill which is going through the House of Lords later this month.
The legislation could impose a duty on NHS bodies to disclose private patient data to police to prevent serious violence and crucially sets aside a duty of confidentiality on clinicians collecting information when providing care.
Dr Byrne said doing so could “erode trust and confidence, and deter people from sharing information and even from presenting for clinical care”.
She added that it was not clear what exact information would be covered by the bill: “The case isn’t made as to why that is necessary. These things need to be debated openly and in public.”
On the dangers of CBDCs
I can’t remember the last time I used cash. Or rather, I can (for my son’s haircut) because it was so unusual; it’s been about 18 months since my default wasn’t paying via the Google Pay app on my smartphone.
As a result, and because I also have played around with buying, selling, and holding cryptocurrencies, that a Central Bank Digital Currency (CBDC) would be a benign thing. Sadly, as Edward Snowden explains, they really are not. His latest article is well worth a read in its entirety.
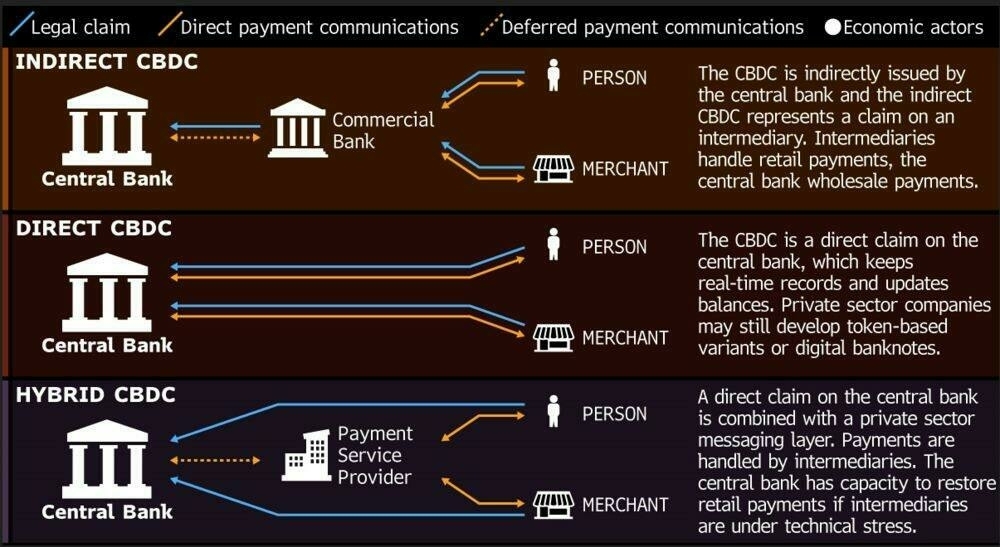
Rather, I will tell you what a CBDC is NOT—it is NOT, as Wikipedia might tell you, a digital dollar. After all, most dollars are already digital, existing not as something folded in your wallet, but as an entry in a bank’s database, faithfully requested and rendered beneath the glass of your phone.Source: Your Money and Your Life - by Edward Snowden - Continuing Ed — with Edward SnowdenNeither is a Central Bank Digital Currency a State-level embrace of cryptocurrency—at least not of cryptocurrency as pretty much everyone in the world who uses it currently understands it.
Instead, a CBDC is something closer to being a perversion of cryptocurrency, or at least of the founding principles and protocols of cryptocurrency—a cryptofascist currency, an evil twin entered into the ledgers on Opposite Day, expressly designed to deny its users the basic ownership of their money and to install the State at the mediating center of every transaction.
Criminals' right to be forgotten
This is interesting: the Associated Press are no longer going to name people involved in minor crimes. I have to agree with their rationale.
These minor stories, which only cover an arrest, have long lives on the internet. AP’s broad distribution network can make it difficult for the suspects named in such items to later gain employment or just move on in their lives.Source: AP Definitive Source | Why we’re no longer naming suspects in minor crime storiesBroadly speaking, when evaluating such stories, we should consider first whether the story is worthy of our news report, and if distributing it is indeed useful to our members and customers. If the answer is yes, in keeping with AP’s commitment to fairness, we now will no longer name suspects in brief stories about minor crimes in which there is little chance AP will provide coverage beyond the initial arrest.
The end of cookie banners?
This is the draft a new standard (spec) to hopefully get rid of those annoying cookie banners. We went through all of this with Do Not Track, so let’s see if this approach ends up working… 🤞

ADPC is a proposed automated mechanism for the communication of users’ privacy decisions. It aims to empower users to protect their online choices in a human-centric, easy and enforceable manner. ADPC also supports online publishers and service providers to comply with data protection and consumer protection regulations.Source: ADPC: A Human-centric and Enforceable Privacy Specification
Screenshot culture
I’d love to see a longer article about this because discussing the role screenshots play in our increasingly-digitally-mediated culture is fascinating to me. Especially as they’re so easy to fake.
But the most important trait of screenshots now is that they’re slippery: A personal exchange can become a meme or a weapon; a random moment can turn into a work of art or mutate into a callout. The alt-lit community—the internet’s short-lived literary movement—was founded by people who used screenshots of text messages, Gchat conversations, and Snapchats to make poems and digital art. It was later blown up by alleged sexual predators who were exposed via screenshots of their other messages, which circulated on Tumblr and Twitter. The rapper 50 Cent published text-message screenshots on Instagram in which he berated Randall Emmett, the husband of a Vanderpump Rules cast member, for being late on a debt payment, but no one remembers that original tough talk. They remember that Emmett wrote “I’m sorry fofty” over and over, inexplicably, a phrase that lives forever on Etsy—you can get it on a T-shirt, a tote, a wine glass, a onesie. (I received a sparkling im sorry fofty coaster for my birthday last year.)Source: Screenshots, the Gremlins of the Internet - The AtlanticThese transformations lend a spectral quality to screenshots: Corry calls them the “evidentiary technique haunting the online realm.” Her recent paper examines the case of the former New York representative Anthony Weiner, who was humiliated by the leak of a lewd Twitter message in 2011, leading to his resignation from Congress. Two years later, more screenshots of more NSFW online messages leaked to the press, effectively ending his run for New York City mayor; and three years after that, it happened again, becoming an unexpected and wild tabloid story in the run-up to the 2016 election. (Weiner was later convicted of a felony for sending explicit messages to a 15-year-old, and served 18 months in prison.) Reporting on his downfall suggested that a lack of tech savvy played a role: If Weiner had known anything about anything, he would have come up with some better operational security. He was condemned for his predatory behavior, but also mocked for “not knowing how to use the internet,” Corry told me—a shame on top of a shame. How could you be so clueless as to not fear the ever-lurking screenshot?
Wherefore art thou, privacy?
As John Naughton points out, if Apple are the only Big Tech company truly interested in preserving our privacy, we should be worried.

So here’s where we are: an online system has been running wild for years, generating billions in profits for its participants. We have evidence of its illegitimacy and a powerful law on the statute book that in principle could bring it under control, but which we appear unable to enforce. And the only body that has, to date, been able to exert real control over the aforementioned racket is… a giant private company that itself is subject to serious concerns about its monopolistic behaviour. And the question for today: where is democracy in all this? You only have to ask to know the answer.Source: If Apple is the only organisation capable of defending our privacy, it really is time to worry | John Naughton | The Guardian
GCHQ violates our privacy
Hardly surprising, but it’s important people are still pushing on this eight years(!) after the Snowden revelations. It’s incredible to me how The Guardian and other outlets can reveal this kind of thing along with the financial corruption set out in the Panama Papers and so little changes as a result.

In Tuesday’s ruling, which confirmed elements of a lower court’s 2018 judgment, the judges said they had identified three “fundamental deficiencies” in the regime. They were that bulk interception had been authorised by the secretary of state, and not by a body independent of the executive; that categories of search terms defining the kinds of communications that would become liable for examination had not been included in the application for a warrant; and that search terms linked to an individual (that is to say specific identifiers such as an email address) had not been subject to prior internal authorisation.Source: GCHQ’s mass data interception violated right to privacy, court rules | GCHQ | The Guardian
Criticism, like lightning, strikes the highest peaks


🙏 Blogging as a forgiving medium — "The ability to “move it around for a long time” is what I’m looking for in a writing medium — I want words and images to be movable, I want to switch them out, copy and cut and paste them, let them mutate. "
I love the few minutes after I press publish on a post, which feels like a race against time between me and the first readers of it. Who will spot the typos and grammatical errors first?
📝 Open working blog and weeknotes templates — "We wrote a guide on how to write weeknotes for Catalyst projects. It is based on Sam Villis’ guide and the templates here are based on Sam’s guide too."
This is useful, especially if you're not blogging yet (or haven't for a while!)
⌚ How to be more productive without forcing yourself — "Basically, if you’re addicted to any of the high-dopamine, low-effort activity, please quit it. At least temporarily so you can reestablish a healthy relationship to work. The more experienced we’re about the topic, the more obvious this is. There is no other way than to temporarily quit the addiction."
I like the practical advice in this article. Too many people do stuff that's too low-value, thus squandering their talent and ability to take on more important stuff.
🤔 Objective or Biased — "This type of analysis software is not widely used in recruiting in Germany and Europe right now. However, large companies are definitely interested in the technology, as we learn during off-the-record conversations. What seems to be attractive: A shorter application process which can save a lot of resources and money."
This is kind of laughable and serious at the same time. I've felt the pain of hiring but, as this research shows, automating the hard parts doesn't lead to awesome results.
📱 Contact-tracing apps were the biggest tech failure of the COVID-19 pandemic — "The system itself, on a technical level, is the root of the problem. In an effort to provide something that could be used universally, while also protecting users’ privacy, Google and Apple came up with a system that was doomed to be useless."
My concern here is that the fault for the failure will be placed at the door of privacy activists.
Quotation-as-title by Baltasar Gracián. Images by Vera Shimunia, Russian textile artist via #WOMENSART