
GPQA is difficult enough to be useful for scalable oversight research on future models significantly more capable than the best existing public models
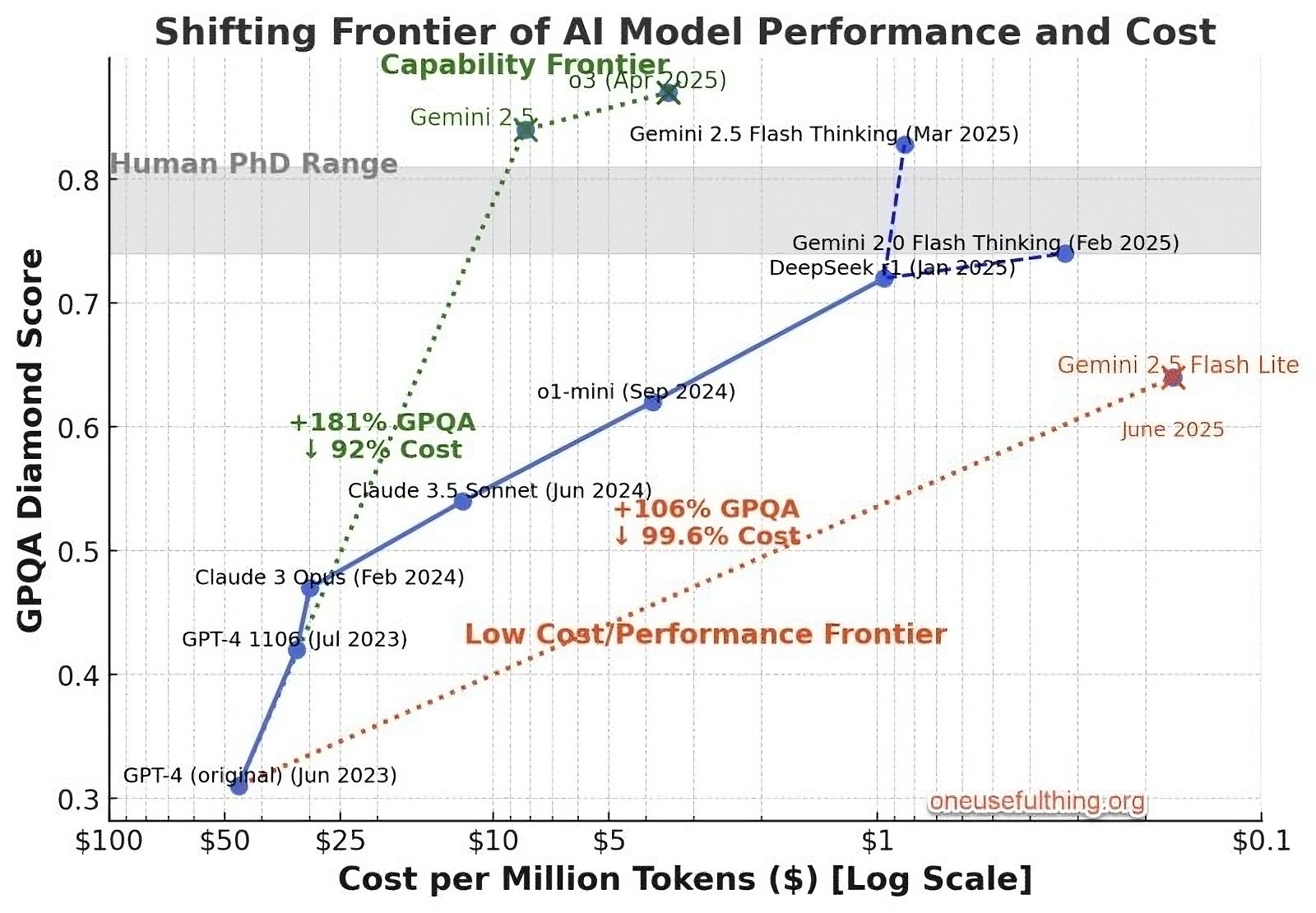
The GPQA is “a challenging dataset of 448 multiple-choice questions written by domain experts in biology, physics, and chemistry” where even experts with unrestricted access to the web only reach 64% accuracy. It’s a benchmark used to rate generative AI models and, as Ethan Mollick notes using the chart he created above, they’re getting better at the GPQA even while the cost is coming down.
I used MiniMax Agent today, a new agentic AI webapp based on MiniMax-M1, “the world’s first open-source, large-scale, hybrid-attention reasoning model” according to the press release. It was impressive, both in terms of capability and flexibility of output. The kind of chain-of-reasoning it uses is going to be very useful to knowledge workers and researchers like me.
MiniMax-M1 is probably on a par with the ChatGPT o3 model, but of course it’s both Chinese and open source, so a direct competitor to OpenAI. I stopped using OpenAI’s products in January when it became clear that using them involved about the same level of associated cringe as driving a Tesla in 2025.
The questions are reasonably objective: experts achieve 65% accuracy, and many of their errors arise not from disagreement over the correct answer to the question, but mistakes due to the question’s sheer difficulty (when accounting for this conservatively, expert agreement is 74%). In contrast, our non-experts achieve only 34% accuracy, and GPT-4 with few-shot chain-of-thought prompting achieves 39%, where 25% accuracy is random chance. This confirms that GPQA is difficult enough to be useful for scalable oversight research on future models significantly more capable than the best existing public models.
Sources: arXiv & Ethan Mollick | LinkedIn